

Il TOP-IX (TOrino Piemonte – Internet eXchange) è il consorzio che gestisce dal 2002 l’Internet eXchange Point (IXP) di Torino. La finalità di questo consorzio — in qualità di IXP neutrale — è di permette a diversi Internet Service Provider (ISP) di scambiare traffico fra di loro, interconnettendo i propri Autonomous System (AS) attraverso accordi di mutuo scambio di dati (peering) al fine di guadagnare in velocità, efficienza e costi di interconnessione. Insieme al MIX di Milano e al NaMeX di Roma, il TOP-IX è uno dei tre principali IXP su cui si basa l’intera infrastruttura della rete internet italiana.
Il TOP-IX è composto da 86 membri consorziati, tra questi — oltre i maggiori carrier nazionali — vi sono anche alcune delle principali realtà del mondo accademico e produttivo del quadrante nord-ovest italiano: il quotidiano La Stampa, il Politecnico di Torino, la banca Intesa San Paolo, la Fondazione Ugo Bordoni, il Traforo del Frejus, l’INrIM (ex Istituto Galileo Ferraris) il Comune di Torino e la Regione Piemonte. Le reti connesse con il Consorzio sono complessivamente un centinaio, di cui circa 40 in remote peering attraverso le partnership strette dal TOP-IX con LyonIX, Vsix, FranceIX, Console-Ixreache con IXPConnect.
L’interruzione dei servizi di connettività
Dopo questa doverosa premessa, necessaria ad inquadrare l’importanza che il TOP-IX riveste nel panorama nazionale, veniamo all’incidente di Martedì 14 Marzo 2017 quando si è verificata una grave anomalia che ha provocato l’interruzione totale dei servizi di connettività e di interscambio di traffico del TOP-IX dalle 11:40 alle 12:45 circa.

Alle 12:09 l’account Twitter di @top_ix informava che “abbiamo un guasto bloccante sulla piattaforma dell’Internet Exchange. I nostri tecnici stanno lavorando per ripristinare il servizio”, per poi annunciare alle 13:01 che “il problema sull’Internet Exchange è stato risolto. Ci scusiamo per l’inconveniente”.
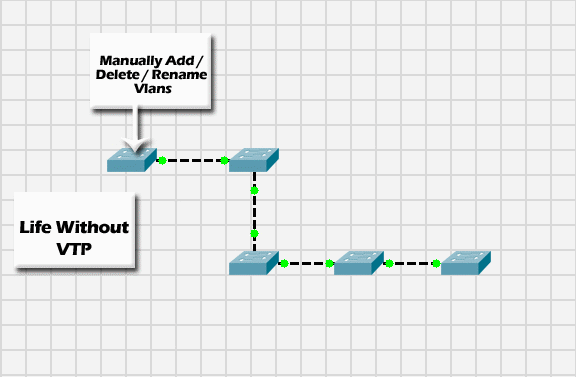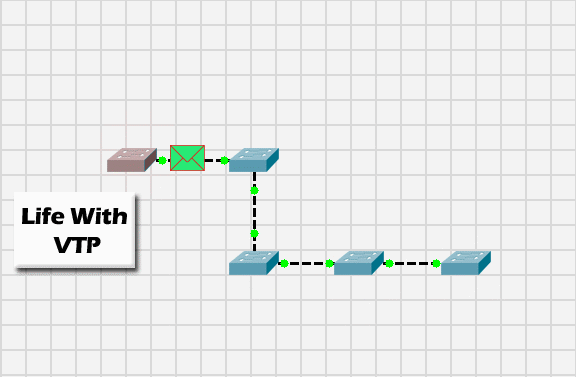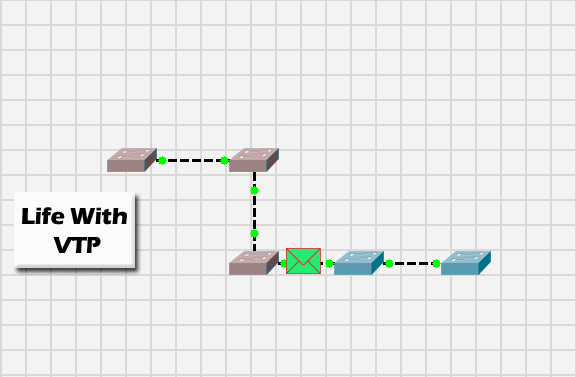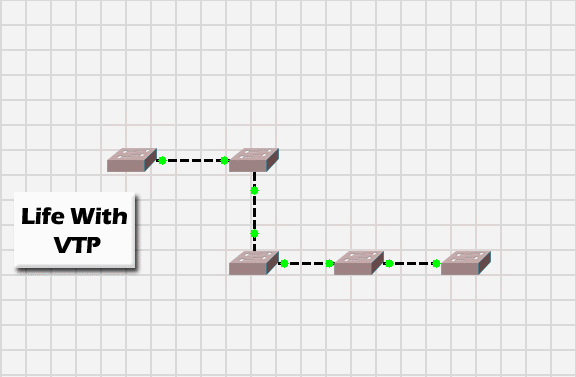
Da quanto è successivamente emerso attraverso un comunicato rilasciato il 22 Marzo, la natura del problema che ha provocato l’interruzione è da ricercare nel Virtual Trunking Protocol (VTP) con il quale gli apparati di rete (switches e routers) distribuiscono e sincronizzano le informazioni relative alle VLAN attive sull’infrastruttura.
La VLAN è una tecnologia che permette di incapsulare differenti reti locali (LAN) — logicamente non comunicanti tra di loro — all’interno di una stessa infrastruttura fisica di rete. Il protocollo VPT è utilizzato sugli apparati Cisco per distribuire e sincronizzare le informazioni relative alle VLAN sui diversi dispositivi che compongono l’infrastruttura, senza doverli configurare singolarmente.
Source: https://commons.wikimedia.org
In base a quanto dichiarato dal TOP-IX la compromissione dell’integrità del database delle VLAN è stato provocato da una anomalia che ha coinvolto il protocollo VPT ed ha causato il blocco totale di tutta l’infrastruttura per circa 1 ora. Il Consorzio rassicura comunque che “sono state prese adeguate misure per evitare la possibilità che l’evento possa ripetersi in futuro” senza però entrare nel merito delle procedure di sicurezza adottate a tale scopo, né spiegando le origini che possono aver causato tale compromissione.
Secondo Wikipedia le maggiori problematiche relative alla configurazione del VTP sono comunque di origine operativa e “si verificano quando si aggiunge all’ambiente di produzione uno switch proveniente da un ambiente di test. Questo dispositivo potrebbe infatti avere un revision number maggiore rispetto a quello dell’ambiente di produzione con il rischio di diffondere informazioni su VLAN inesistenti o differenti”. Questa è ovviamente solo una mia congettura non supportata da alcun elemento probatorio ma solo da una semplice verifica effettuata con l’enciclopedia collaborativa di Wikipedia.
Considerazioni
Come già descritto in un precedente post dal titolo “NaMeX down” personalmente ritengo che anche questo incidente dovrebbe essere interpretato come una grande opportunità per ogni infrastruttura per valutare e testare i propri piani di business continuity e di disaster recovery. Una specie di full interrupt test che nessuna simulazione potrà mai replicare in maniera così realistica.
L’esposizione al rischio di strutture complesse — come gli IXP — è inevitabile e l’evento del TOP-IX non è un caso isolato. Ne è testimonianza anche il recente incidente di Amazon che lo scorso 28 Febbraio — come abbiamo documentato in “Amazon AWS down” — ha visto una discreta porzione di internet andare fuori uso per diverse ore a causa di un banale errore di digitazione (typo) da parte di un singolo operatore che ha bloccato un intero data center.
Questi eventi ci portano di nuovo a riflettere sulla fragilità di internet quando non vengono applicati tutti i principi della sicurezza informatica. In questo settore non esistono, né esisteranno in futuro soluzioni onnicomprensive in grado di azzerare completamente il rischio. Possiamo però mitigarlo per ottenere un livello accettabile di esposizione attraverso una corretta politica di risk management che possa quantomeno circoscrivere i danni.
Un doveroso ringraziamento merita comunque la direzione del TOP-IX per la sua trasparenza e la tempestività con cui ha saputo gestire l’incidente e rilasciare le necessarie — se pur minimali — informazioni sull’evoluzione degli eventi. Un raro esempio di correttezza verso tutta la community — non solo verso gli stakeholders — a cui chiunque dovrebbe ispirarsi nella gestione emergenziale degli incidenti informatici aziendali.
