Italia

Pubblichiamo il primo di due saggi sul web semantico, scritto da Ignazio Licata (Isem, Institute for Scientific Methodology, Palermo). Un ringraziamento particolare dell’autore a Emanuele Somma, Michele Monti e Matteo Giacomazzi di Infomedia e a “Computer Programming”.
Il secondo pezzo sarà pubblicato domani
1. Il problema della rappresentazione della conoscenza e l’approccio sistemico-cibernetico
L’intera storia dell’intelligenza artificiale può essere caratterizzata come il tentativo di trasformare in modelli formali una formidabile serie di questioni appartenenti alla secolare tradizione filosofica sulla natura della conoscenza (gnoseologia). Il concetto stesso di “agente intelligente” infatti implica una “descrizione del mondo” in base alla quale l’agente, in interazione con l’ambiente, opera le sue scelte attraverso l’attivazione di una serie di strategie di valutazione dei dati e selezione degli elementi significativi in relazione ad un obiettivo prefissato.
I vecchi approcci dell’IA cosiddetta “forte”, basata essenzialmente sul cognitivismo, erano centrati sull’idea di poter dare una descrizione esauriente di queste attività utilizzando gli strumenti della logica formale, eventualmente integrati con un set di regole euristiche, ed opportuni linguaggi di programmazione in grado di implementare questi formalismi.
Ricordiamo che il cognitivismo ha le sue radici in un programma di psicologia scientifica basato sull’idea che un “processo cognitivo” può essere completamente descritto tramite una serie di procedure specificabili in modo rigoroso con un livello di dettaglio molto elevato. L’assunzione centrale del programma IA “forte” consiste dunque nell’idea che un processo di questo tipo può essere anche piuttosto complicato, ma che il modello può essere opportunamente “complessificato” in modo da renderlo capace di prestazioni sempre più sofisticate e confrontabili con quelle di un agente intelligente naturale. Questo può essere fatto seguendo due vie: da una parte ampliando la descrizione del mondo, inteso come enti in relazione tra loro; dall’altra raffinando le strategie che permettono ad un sistema intelligente, stabilito un obiettivo, di raggiungerlo attivando una serie di risorse descrivibili come passi in grado di ottimizzare in vari modi il raggiungimento del risultato utilizzando la descrizione del mondo e le regole procedurali.
In questo modo il modello cognitivo viene ad avere una duplice valenza: da una parte il valore che possiamo definire “ingegneristico”, legato all’utilità “pratica” di sistemi intelligenti artificiali, dall’altra quello più specificatamente epistemico, ossia la capacità di essere un modello “realistico” del modo di lavorare dei sistemi naturali.E’ ben comprensibile come un programma di questo tipo potesse meritarsi l’appellativo di “forte”. Infatti la riuscita di entrambi gli obiettivi può essere riassunta in modo suggestivo dicendo che la mente è un programma, per quanto complesso! Si tratta di una posizione teorica sulla natura della mente che tende a ritenere inessenziali i dettagli dell’hardware (biologico o artificiale), la cui unica funzione è quella di supportare il “programma-mente”, e che può richiedere per questo una maggiore o minore capacità di elaborazione, ma che non presenta in linea di principio problemi di carattere teorico.Questo non vuol dire in alcun modo che ci si aspetta un “isomorfismo” strutturale tra l’hardware “naturale”, prodotto da millenni di evoluzione biologica, e quello artificiale, frutto dell’attività modellistica; piuttosto l’analogia è spostata sulle attività cognitive, intese come passi procedurali di un software “mentale”. Si può ben vedere come un’impostazione di questo tipo richiami il cartesian cut tra mente e materia, e stabilisce una separazione piuttosto netta tra informazione ed energia, che invece in natura sono sempre strettamente connesse attraverso processi dissipativi che permettono una continua elaborazione e riorganizzazione dell’informazione, ma soprattutto l’acquisizione e la produzione di nuova informazione. In particolare si è assunto per lungo tempo che il modello della Turing-Computabilità potesse rendere conto degli aspetti delle computazione biologica, che appare invece richiedere un approccio teorico nuovo visto che i sistemi naturali mostrano contemporaneamente aspetti sub & super Turing, in grado di lavorare efficacemente anche in situazioni di rumore, incompletezza e fuzziness attraverso sofisticate procedure di appropriazione semantica dell’informazione (Licata, 2003;2004; 2008).
A lungo andare sono apparsi evidenti i limiti dell’impostazione cognitivista, ed i suoi risultati vanno valutati molto diversamente in relazione alle due ambizioni originali, quella ingegneristica e quella epistemica. Questa duplice aspettativa non si è realizzata nello stesso modo. I ben noti “sistemi esperti” nei più svariati campi- scacchi, strategie militari, economiche, diagnosi mediche- utilizzano concettualizzazioni e strumenti formali diversi, ma sono accomunati da quella che potremmo definire una rappresentazione statica della conoscenza. Una descrizione del mondo ed una serie di regole di produzione sempre accessibili e completamente definite portano inevitabilmente ad un dominio semantico limitato. Questo vuol dire che al di fuori delle situazioni per le quali il sistema è stato progettato viene a cadere l’univocità tra procedure e descrizione del modo basate sul “patto sintattico” che è proprio di questi approcci. L’idea di ampliare lo “spessore semantico” dell’informazione utilizzata dal sistema ampliando lo scenario (regole, descrizione) porta ad alcuni aspetti paradossali. Infatti, se anche fosse possibile includere nel nostro modello ogni dettaglio della descrizione del mondo, ed ogni possibile azione su di esso, questo significherebbe che il sistema è strettamente deterministico, in aperto contrasto con ciò che conosciamo dei processi biologici e della cognizione naturale.
Gli approcci connessionisti, basati sulle reti neurali e sui sistemi distribuiti paralleli, hanno aperto nuovi scenari legati ad una diversa e più stretta relazione tra sistema ed ambiente che può essere colta utilizzando l’approccio sistemico-cibernetico, sviluppato tra gli altri da N. Wiener, L. Von Bertalanffy, R. Ashby, H. Von Foerster,, H. Maturana e F. Varela. In questo caso non si dà descrizione del mondo senza considerare l’osservatore, sistema che interagisce con altri sistemi e seleziona l’informazione in relazione in relazione alla sua struttura interna, ed alla sua storia dinamica. Tra osservatore (sistema intelligente) ed osservato( mondo ), non c’è più una relazione lineare e deduttiva, fissata una volta per tutte in un modello formale, ma una relazione circolare basata su una strategia di adattamento e coevoluzione continua. Questo implica almeno due differenze notevoli con l’approccio cognitivista sopra delineato. Innanzitutto è necessario considerare una relazione di apertura termodinamica tra sistema ed ambiente. Informazione ed energia costituiscono un flusso che attraversa e ridefinisce continuamente le relazioni e la struttura di entrambi. Questa è una condizione necessaria ma non sufficiente, riassumibile dicendo che un sistema intelligente deve essere un sistema dissipativo. Inoltre è necessario che il sistema possieda apertura logica, ossia esibisca comportamenti emergenti legati allo stato dinamico delle relazioni sistema-ambiente, in grado di pilotare il sistema verso situazioni adattive sempre più complesse attraverso la produzione di nuova informazione. In questo tipo di rappresentazioni non c’è più dunque una descrizione del mondo definita ed indipendente dall’agente, ma è piuttosto l’esplorazione del mondo da parte dell’agente che genera continuamente processi di auto-organizzazione adattativi che fissano, ad un istante dato, una descrizione del mondo legata alla struttura ed agli obiettivi dell’agente.E’ possibile dimostrare che ciò implica una codifica dell’informazione strettamente correlata allo stato del sistema e non “trasportabile” I modelli cognitivisti corrispondono all’adozione di modelli a bassa apertura logica, che possono essere visti come “sezioni temporali fisse” di una rappresentazione della conoscenza che nei sistemi naturali è sempre dinamica.
Questo approccio ha avuto un impatto significativo non soltanto sugli aspetti teorici della questione, ma anche sulla tecnologia dei motori di ricerca, che sono uno dei campi di prova decisivi dei modelli di rappresentazione della conoscenza. Vediamo più da vicino adesso alcune linee di ricerca in queste direzioni.
2 Dalle ontologie alle rappresentazioni ontodinamiche.
Lo sviluppo progressivo dei vecchi “sistemi esperti” in forme di rappresentazione della conoscenza sempre più potenti e “flessibili” ha prodotto una maggiore riflessione filosofica sugli aspetti gnoseologici e cognitivi della acquisizione, validazione, configurazione, e comunicazione della conoscenza. Tutte queste fasi sono strettamente legate tra loro, e stabiliscono ognuna una correlazione tra sistema cognitivo ed ambiente. Il problema classico della realizzazione di una rappresentazione della conoscenza è quello mettere a disposizione di altri sistemi cognitivi l’informazione prodotta e strutturata da un particolare agente. Questa operazione di “mediazione” impone una classificazione dei vari modelli di conoscenza. Un primo modello è quello mimetico-rappresentativo, che agisce per icone, ed è direttamente collegato alle caratteristiche genetiche, sensoriali, percettive dell’agente situato.Potrebbe definirsi anche ” a contesto dinamico”, poiché le icone della conoscenza vengono fornite di volta in volta dall’attivazione di risorse in risposta ad una serie di esigenze e stimoli.Questa conoscenza è difficilmente “estraibile” dall’agente, ed entra qui in gioco il modello proposizionale, che è quello più tradizionale del procedimento scientifico dell’IA simbolica-cognitivista .L’attenzione qui si sposta sulle relazioni tra classi di enti, anziché sugli oggetti della percezione-rappresentazione contestualizzata e centrata sull’utente.Entrano a questo punto le tecniche procedurali e dichiarative, entrambe unite da un approccio che possiamo definire “sintattico”: la conoscenza, infatti, viene vista essenzialmente- almeno dal punto di vista ingegneristico- come una manipolazione di strutture linguistiche,del resto facilmente implementabili nei sistemi di elaborazione.
La riflessione sui limiti e le possibilità di queste strutture hanno portato alle genesi di un nuovo capitolo nei sistemi di rappresentazione della conoscenza,ormai molto lontani dall’ingenuità dei vecchi sistemi esperti,e molto ambiziosi sia dal punto di vista filosofico che da quello applicativo.Una Ontolingua si presenta come la “specificazione di una concettualizzazione”, secondo l’ormai classica definizione di Gruber (1993).Si tratta sostanzialmente della possibilità di rendere sempre più articolata la relazione tra il livello dichiarativo e quello procedurale, in modo da poter avere delle rappresentazioni della conoscenza suscettibili di drastici cambiamenti di dominio, corrispondenti a concettualizzazioni diverse e dunque più orientate alle finalità dell’utente. Per raggiungere questo scopo si è utilizzato il calcolo dei predicati del primo ordine ed elementi essenziali del ragionamento non-monotono.Anche con questa scelta è possibile distinguere qui due scuole fondamentali: una tipicamente europea, che mira a strutturare la concettualizzazione in base a criteri del tutto generali, ad esempio proponendo modelli per la generalizzazione o restrizione dei domini concettuali che gestiscono dall’alto (top-down) l’intero sistema; l’altra scuola è più pragmaticamente americana, e sostiene la necessità di un ampliamento mirato ai processi in gioco ed ai fini dell’utente, senza fare affidamento ad alcun criterio predefinito.
Quello che qui ci chiediamo è non in cosa differiscono questi due approcci, ma piuttosto cerchiamo di individuare quello che hanno in comune. Innanzitutto, una visione dell’ontologia come teoria linguistica degli enti. Questo implica due assunzioni piuttosto forti:
a) la “neutralità” dell’ontologia, formalizzata attraverso il calcolo proposizionale e posta alla base della “portabilità” del sistema, ossia la sua possibilità di costruire diverse concettualizzazioni;
b) La possibilità di descrivere il Mondo attraverso le unità discrete della logica dei predicati.
Abbiamo visto che sistemi di questo tipo hanno delle grosse difficoltà nella gestione dei significati al di fuori dei domini semantici (micro-mondi) per i quali sono stati progettati,e la capacità di elaborare nuovo significato è un’espressione di emergenza intrinseca legata al costituirsi di nuovi codici che veicolano la gestione dell’informazione in relazione al grado di apertura logica del sistema, e dunque delle sue relazioni con l’ambiente(Licata,2009). E’ possibile dimostrare che più è alto il grado di apertura logica di un sistema più è possibile considerarlo autonomo nel senso di Wiener-Maturana-Varela-Bateson.Si tratta di un sistema in grado di esibire coerenza, chiusura operazionale (auto-comportamenti) e produzione di un mondo tramite processi di emergenza intrinseca. Al contrario, i sistemi eteronomi sono basati su una logica di corrispondenza, su relazioni di input/output ed il loro modo di interazione caratteristico è quello istruttivo-rappresentazionale. Si tratta dunque di sistemi a bassa apertura logica.
E’ evidente dall’analisi dei punti (a) e (b) che i modelli ontologici fin qui proposti, pur nella loro diversità, sono accomunati dall’essere più simili a modelli eteronomi a bassa apertura logica che a sistemi ad alta apertura logica autonomi. Questo vuol dire che i processi di creazione di significato non sono centrati sull’utente, ma gestiti da questo all’interno di un mondo piuttosto rigido. L’esigenza che qui si pone è dunque quella di ottenere processi di emergenza intrinseca centrati sul rapporto dialogico tra sistema ed utente, e dunque è necessario passare dai modelli ontologici ai modelli ontogenetici, in cui si considera l’attività dell’utente-osservatore come centrale nella strutturazione del panorama della conoscenza.
3- Un sistema dinamico per l’acquisizione di conoscenza
Come scrive Von Foester: “Se si assume questa posizione dialogica allora non possiamo più porci delle domande ingenue del tipo ‘ qual’è la risposta di B alla domanda di A?’. Il problema diventa ‘Qual’è l’interpretazione di A della risposta di B all’interpretazione di B delle domanda di A?”
Questo ha spostato l’attenzione verso modelli di ispirazione biomorfa le cui caratteristiche generali possono descrivere gli aspetti ontodinamici della rappresentazione della conoscenza e ad ampliarne l’apertura logica rispetto a modelli più tradizionali.La situazione che abbiamo studiato è legata all’attività di text-analysis (Licata et al.,2006; Licata, 2009).
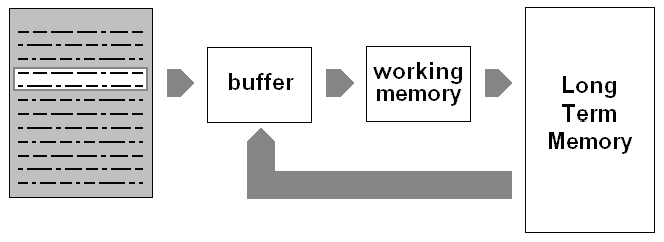
(Guarda raffigurazione schema generale di un sistema di questo tipo)
La parte del contenuto del documento che si sta analizzando (quella presente nel buffer) dovrebbe essere opportunamente codificata tenendo conto del contesto in cui è collocata. Il contesto rappresenta il tema, l’argomento trattato dalla parte del contenuto elaborato e per individuarlo correttamente occorre considerare non solo l’informazione che è stata già analizzata nel documento, ma anche quella che è possibile richiamare dalla struttura che rappresenta la conoscenza accumulata nel corso delle varie analisi effettuate in precedenza (Long Term Memory).
In questo modo è possibile variare dinamicamente il contenuto della LTM, senza cioè ripresentare ogni volta al sistema tutti i documenti analizzati in precedenza ma solo quelli che il sistema non conosce.
Durante la fase della interpretazione della nuova informazione è necessario richiamare parte della conoscenza contenuta nella memoria a lungo termine. Nella definizione delle modalità di recupero di tale informazione si è fatto riferimento al modello della memoria di lavoro a lungo termine sviluppato da Ericsson e Kintsch (1999). Questi due ricercatori hanno innanzitutto definito una nuova forma di rappresentazione della conoscenza simile ad una rete associativa, in cui ogni nodo però è rappresentato da una proposizione esprimibile attraverso un predicato n-ario come ad es. GIVE[MARY,BOOK,FRED]. Tale formalismo, a detta dei loro sviluppatori, è il più generale che sia mai stato definito e combina ed estende gli aspetti vantaggiosi di tutti i sistemi di rappresentazione classici (feature systems, reti associative, reti semantiche, scripts, frames etc.).
Secondo tale formalismo il significato di un nodo è dato non tanto dalla sua posizione nella rete (che rappresenta comunque il modo in cui è stato concettualizzato, assimilato dal sistema), ma dai nodi vicini che si attivano in presenza delle altre informazioni che vengono analizzate nello stesso momento e che rappresentano quindi il contesto in cui è inquadrabile il concetto.
L’adozione di una rete di proposizioni come rappresentazione della conoscenza presenta indubbiamente dei grossi vantaggi rispetto alle più classiche forme di rappresentazione. Rispetto alle reti semantiche, ai frames e agli scripts, che tendono ad organizzare la conoscenza in maniera più ordinata e più logica, le reti di proposizioni si presentano più disorganizzate e caotiche, ma godono del non trascurabile vantaggio che sono capaci di variare dinamicamente non solo nel tempo, sulla base delle esperienze passate, ma anche in base al contesto percepito. Non a caso Kintsch le definisce espressamente strutture emergenti.
Queste strutture emergenti si presentano nel nostro modello come particolari cluster di nodi misurati attraverso un coefficiente di coerenza che misura, in un certo senso, l’aggregazione dinamica dei nodi in relazione allo stato globale sistema-utente. La cosa può anche essere vista come se il sistema creasse, di volta in volta, un modello interno dell’utente, attivando quei significati che sono legati al particolare modello di utente. Una caratteristica fondamentale è il processo di aggiornamento dei cluster, che avviene attraverso un processo diffusivo che ri-organizza
Il confronto diretto con strutture cognitive simili ricavate da un gruppo di soggetti umani (mediante ad esempio esperimenti di libere associazioni di parole) permetterà di valutare se il sistema è in grado di assimilare i concetti nello stesso modo in cui lo farebbe un utente umano. Al momento i valori calcolati del coefficiente di coerenza confermano solo che tale rappresentazione evolve secondo un determinato schema. Resta da verificare ora la correttezza di tale schema. Interessante è anche la statistica dei cluster. Questa appare simile a quella di una struttura frattale scale-free, ossia non caratterizzata da un’unica predominante scala rappresentativa. In altre parole, l’attività di interazione sistema-utente attiva una serie di cluster con una funzione di distribuzione tipica dei sistemi governati da una legge di potenza, in cui avvengono transizioni di fase e processi di auto-organizzazione. Un risultato di questo tipo è stato ottenuto dal fisico teorico L. Barabasi con G. Bianconi,R. Albert e H. Jeong utilizzando gli strumenti caratteristici della fisica statistica nell’analisi delle reti small-worlds che caratterizzano il world wide web. In questa teorizzazione l’uso del formalismo della teoria quantistica dei campi permette di ottenere i nostri cluster come condensati di Bose. Questi sono particolari domini di coerenza che si manifestano in un sistema fisico di bosoni quando la temperatura globale permette l’emergere tra loro di correlazioni energetiche attraverso transizioni di fase, “segno” caratteristico e rigoroso dell’esistenza di processi emergenti. Nel nostro caso la temperatura-energia corrisponde al lavoro d’interazione computazionale tra utente e sistema, e il processo di bosonizzazione è analogo alla creazione di cluster con un alto coefficiente di coerenza. Il punto interessante qui da sottolineare è che metodi diversi mostrano un comportamento globalmente simile, confrontabile su basi rigorose, e tutto ciò sembra suggerire non soltanto una nuova generazione di motori di ricerca in grado di “rappresentare l’utente”, ma soprattutto che i comportamenti dei sistemi complessi, capaci di esibire apertura logica ed emergenza, potrebbe uscire dall’attuale stato naive per trovare un linguaggio matematico unificato sotto forma di un’opportuna estensione dei metodi della teoria quantistica dei campi, creando una nuova era di connessioni tra la ricerca pura e le applicazioni tecnologiche più avanzate.
Bibliografia:
1) L. Magnani, Ingegnerie della conoscenza, Marcos y Marcos, Milano, 1997;
2) I. Licata, Mente e Computazione, in Systema Naturae 5, 2003;
3) I. Licata, Verso una teoria generale dei sistemi intelligenti,in Neuroscienze.net , (1)2004;
4) I. Licata,
5) I. Licata, A Dynamical Model for Information Retrieval and Emergence of Scale-Free Clusters in a Long Term Memory Network, in Emergence, Complexity and Organization, 11, 1, 2009.
6) L. Lella, Analisi della semantica nel WEB attraverso reti neurali auto-organizzanti,Tesi, Università Politecnica delle Marche, aa. 2001-2002;
7) W. Kintsch, V. L. Patel, K. A. Ericsson, The Role of Long Term Working Memory in Text Comprehension, in Psychologia 42, 1999;
8) G. Minati, M.P. Penna, E. Pessa, Thermodynamical and Logical Openness in General Systems, in Syst. Res. And B. Sciences 15, 1998;
9) M. P. Penna, E. Pessa, Can Learning Process in Neural Networks Be Considered as a Phase Transition? In M. Marinaro e R. Tagliaferro (eds), Proc.of the 7th Italian Workshop on Neural Nets, World Scientific , 1995;
10) R. Albert , L. Barabasi, Statistical Mechanics of Complex Networks, in Rev. of Mod. Physics,74,2001;
11) I.Licata, G. Tascini, L. Lella, A. Montesanto, W. Giordano , Scale Free Graphs in Dynamic Knowledge Acquisition in “Systemics of Emergence. Research and Development”, G. Minati, E. Pessa, M. Abram Eds, Springer Publ. , 2006

{kind=link}